Pour Point Extraction#
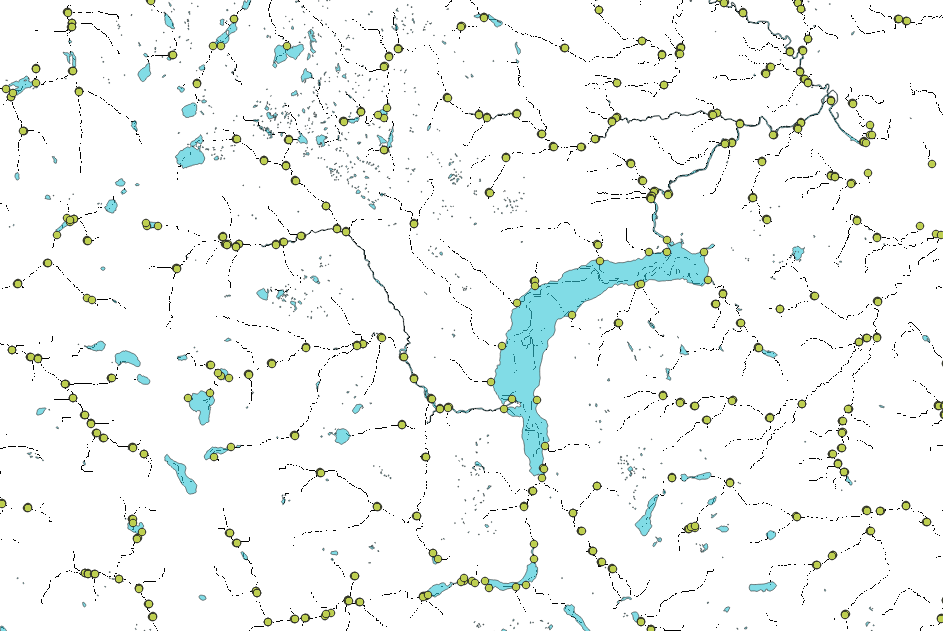
Fig. 5 In this notebook, we will derive a set of pour points describing river confluences. These points will be used to delineate basins and extract basin attributes.#
In this notebook, we’ll use the stream network generated in the previous notebook to find all river confluences. The set of confluences will be filtered using the lake geometries found in the HydroSHEDS dataset geometry to remove spurious confluences within lakes. The remaining points will serve as input for basin delineation.
The following files were pre-processed for the purpose of demonstration since the original files cover all of Canada and are as a result very large. The files below (may) need to be downloaded and saved to content/notebooks/data/region_polygons/.
Vancouver_Island.geojson: this is the polygon describing Vancouver Island. It was used to capture just the waterbody geometries on Vancouver Island.Vancouver_Island_lakes.geojson: the water bodies polygon set for Vancouver Island.
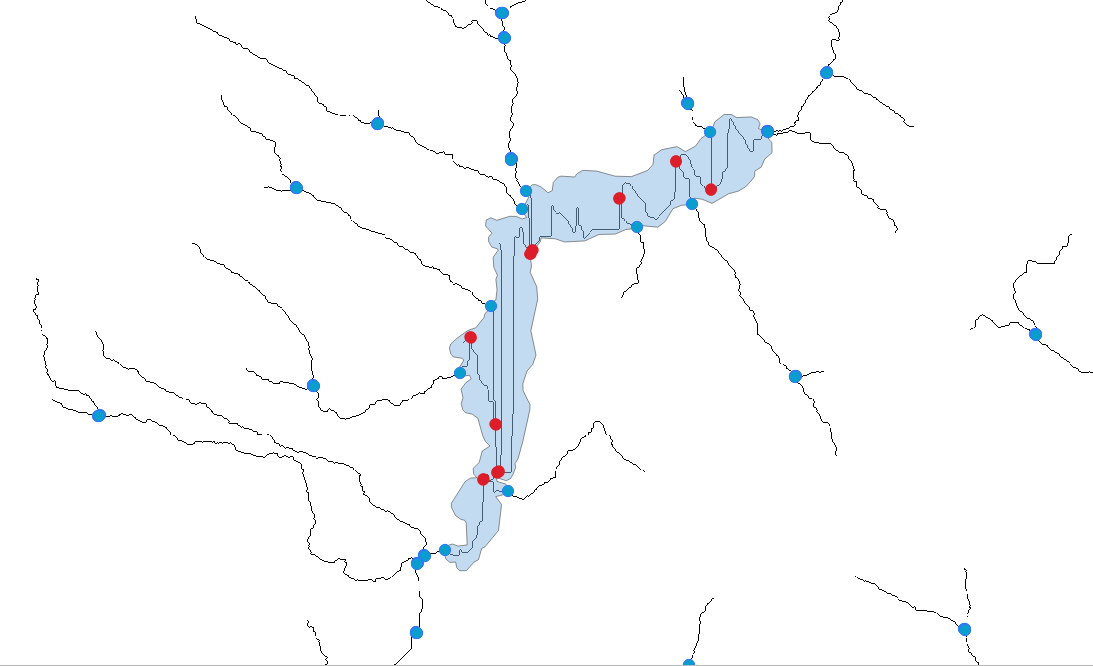
Fig. 6 The steps in this notebook produce a set of river confluences (blue), with spurious points within lakes (red) filtered out. Lake boundaries are traversed to find lake inflows.#
import os
from utilities import *
from shapely.geometry import Point, LineString, Polygon
import multiprocessing as mp
import geopandas as gpd
import time
import numpy as np
import pandas as pd
# open the stream layer
base_dir = os.path.dirname(os.getcwd())
dem_folder = os.path.join(base_dir, 'notebooks/data/processed_dem/')
Note
For clarity, some functions have been relegated to a separate file. To find more detail, see utilities.py.
# Create the folder where the pour point geometry information will be saved.
pour_pt_path = os.path.join(base_dir, f'notebooks/data/pour_points/')
if not os.path.exists(pour_pt_path):
os.mkdir(pour_pt_path)
# import the polygon describing Vancouver Island
region_polygon = gpd.read_file('data/region_polygons/Vancouver_Island.geojson')
Import rasters (flow direction, accumulation, stream network)#
# open the streams dem
region = 'Vancouver_Island'
d8_path = os.path.join(dem_folder, f'{region}_d8_pointer.tif')
acc_path = os.path.join(dem_folder, f'{region}_acc.tif')
stream_path = os.path.join(dem_folder, f'{region}_streams.tif')
# stream_link_path = os.path.join(dem_folder, f'{region}_stream_links.tif')
Here we’ll set a minimum threshold of 5 \(km^2\) to limit the number of confluences for the sake of this demo.
rt0 = time.time()
stream, _, _ = retrieve_raster(stream_path)
# stream_links, _, _ = retrieve_raster(stream_link_path)
fdir, _, _ = retrieve_raster(d8_path)
acc, _, _ = retrieve_raster(acc_path)
resolution = stream.rio.resolution()
dx, dy = abs(resolution[0]), abs(resolution[1])
print(f'Raster resolution is {dx:.0f}x{dy:.0f}m')
# get raster data in matrix form
S = stream.data[0]
F = fdir.data[0]
A = acc.data[0]
stream_crs = stream.rio.crs.to_epsg()
rt1 = time.time()
print(f' ...time to load resources: {rt1-rt0:.1f}s.')
Raster resolution is 22x22m
...time to load resources: 14.1s.
min_basin_area = 5 # km^2
# min number of cells comprising a basin
basin_threshold = int(min_basin_area * 1E6 / (dx * dy))
Create a list of coordinates representing all the stream cells.
# get all the stream pixel indices
stream_px = np.argwhere(S == 1)
Define confluence points in the stream network#
Below we create a dictionary of potential pour points corresponding to confluences.
We iterate through all the stream pixels, retrieve a 3x3 window of flow direction raster around each one, and check if it has more than one stream cell pointing towards it.
ppts = {}
nn = 0
for (i, j) in stream_px:
c_idx = f'{i},{j}'
if c_idx not in ppts:
ppts[c_idx] = {}
ppt = ppts[c_idx]
# Add river outlets
focus_cell_acc = A[i, j]
focus_cell_dir = F[i, j]
ppt['acc'] = focus_cell_acc
if focus_cell_dir == 0:
# the focus cell is already defined as a stream cell
# so if its direction value is nan or 0,
# there is no flow direction and it's an outlet cell.
ppt['OUTLET'] = True
# by definition an outlet cell is also a confluence
ppt['CONF'] = True
else:
ppt['OUTLET'] = False
# get the 3x3 boolean matrix of stream and d8 pointer
# cells centred on the focus cell
S_w = S[max(0, i-1):i+2, max(0, j-1):j+2].copy()
F_w = F[max(0, i-1):i+2, max(0, j-1):j+2].copy()
# create a boolean matrix for cells that flow into the focal cell
F_m = mask_flow_direction(S_w, F_w)
# check if cell is a stream confluence
# set the target cell to false by default
ppts = check_for_confluence(i, j, ppts, S_w, F_m)
Convert the dictionary of stream confluences to a geodataframe in the same CRS as our raster.
output_ppt_path = os.path.join(pour_pt_path, f'{region}_ppt.geojson')
print(output_ppt_path)
if not os.path.exists(output_ppt_path):
t0 = time.time()
ppt_df = pd.DataFrame.from_dict(ppts, orient='index')
ppt_df.index.name = 'cell_idx'
ppt_df.reset_index(inplace=True)
# split the cell indices into columns and convert str-->int
ppt_df['ix'] = [int(e.split(',')[0]) for e in ppt_df['cell_idx']]
ppt_df['jx'] = [int(e.split(',')[1]) for e in ppt_df['cell_idx']]
# filter for stream points that are an outlet or a confluence
ppt_df = ppt_df[(ppt_df['OUTLET'] == True) | (ppt_df['CONF'] == True)]
print(f' There are {len(ppt_df)} confluences and outlets combined in the {region} region.')
else:
print('existing file')
ppt_df = gpd.read_file(output_ppt_path)
/home/danbot/Documents/code/23/bcub_demo/notebooks/data/pour_points/Vancouver_Island_ppt.geojson
There are 22556 confluences and outlets combined in the Vancouver_Island region.
n_pts_tot = len(stream_px)
n_pts_conf = len(ppt_df[ppt_df['CONF']])
n_pts_outlet = len(ppt_df[ppt_df['OUTLET']])
print(f'Of {n_pts_tot} total stream cells:')
print(f' {n_pts_conf - n_pts_outlet} ({100*n_pts_conf/n_pts_tot:.1f}%) are stream confluences,')
print(f' {n_pts_outlet} ({100*n_pts_outlet/n_pts_tot:.1f}%) are stream outlets.')
Of 934639 total stream cells:
21041 (2.4%) are stream confluences,
1515 (0.2%) are stream outlets.
Note
The pour points are thus far only described by the raster pixel index, we still need to apply a transform to map indices to projected coordinates.
ppt_gdf = create_pour_point_gdf(region, stream, ppt_df, stream_crs, output_ppt_path)
ppt_gdf.head()
creating 100 chunks for processing
...10/100 chunks processed in 0.0s
...20/100 chunks processed in 0.1s
...30/100 chunks processed in 0.1s
...40/100 chunks processed in 0.1s
...50/100 chunks processed in 0.2s
...60/100 chunks processed in 0.2s
...70/100 chunks processed in 0.2s
...80/100 chunks processed in 0.2s
...90/100 chunks processed in 0.3s
...100/100 chunks processed in 0.3s
22556 pour points created.
...ppts geodataframe processed in0.3s
| cell_idx | acc | OUTLET | CONF | ix | jx | geometry | |
|---|---|---|---|---|---|---|---|
| 9 | 199,4302 | 22657.0 | True | True | 199 | 4302 | POINT (865049.001 659747.390) |
| 39 | 214,4329 | 21779.0 | False | True | 214 | 4329 | POINT (865649.625 659413.710) |
| 40 | 214,4330 | 18179.0 | False | True | 214 | 4330 | POINT (865671.870 659413.710) |
| 41 | 215,4329 | 3591.0 | False | True | 215 | 4329 | POINT (865649.625 659391.465) |
| 137 | 234,4352 | 11530.0 | False | True | 234 | 4352 | POINT (866161.268 658968.803) |
Filter spurious confluences#
One issue with the stream network algorithm is it does not identify lakes. There are many lakes on Vancouver Island, and we want to remove the spurious confluence points that fall within lakes, and we want to add points where rivers empty into lakes. We can use hydrographic information from the National Hydrographic Netowork to do so.
Tip
Lake polygons for Vancouver Island are saved under content/notebooks/data/region_polygons/Vancouver_Island_lakes.geojson
Get the water body geometries that contain confluence points#
From the NHN documentation:
Permanency code:
-1 unknown
0 no value available
1 permanent
2 intermittent
water_definition |
Label |
Code Definition |
|---|---|---|
None |
0 |
No Waterbody Type value available. |
Canal |
1 |
An artificial watercourse serving as a navigable waterway or to channel water. |
Conduit |
2 |
An artificial system, such as an Aqueduct, Penstock, Flume, or Sluice, designed to carry water for purposes other than drainage. |
Ditch |
3 |
Small, open manmade channel constructed through earth or rock for the purpose of conveying water. |
*Lake |
4 |
An inland body of water of considerable area. |
*Reservoir |
5 |
A wholly or partially manmade feature for storing and/or regulating and controlling water. |
Watercourse |
6 |
A channel on or below the earth’s surface through which water may flow. |
Tidal River |
7 |
A river in which flow and water surface elevation are affected by the tides. |
*Liquid Waste |
8 |
Liquid waste from an industrial complex. |
Warning
The label “10” also exists, though I have not found a corresponding definition. From the image below, it appears they may represent seasonal channels. Light blue regions are lakes (4) and watercourses (6).
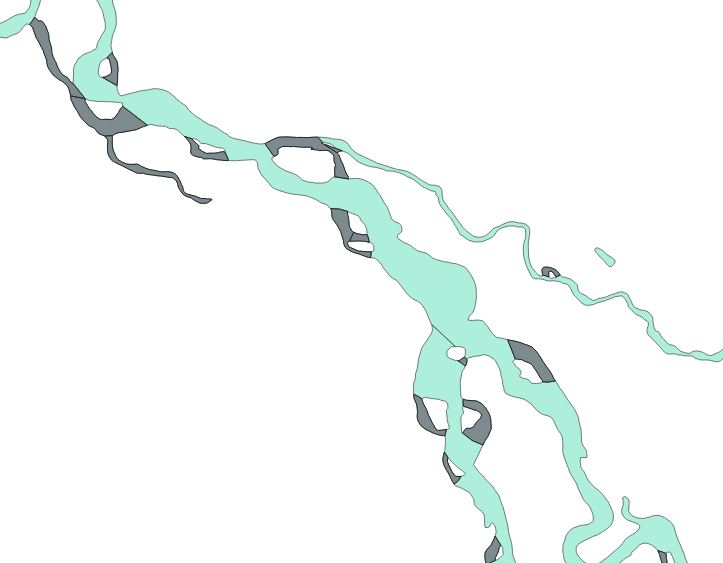
Fig. 7 Darker grey polygons are labeled with the code “10” appear to be seasonal channels.#
Download the lakes geometry from HydroLAKES and update the path below to reflect where it is saved. We first need to clip the data to the region of interest.
def filter_lakes(lakes_df, ppts, resolution):
"""
Permanency code:
-1 unknown
0 no value available
1 permanent
2 intermittent
Args:
wb_df (geodataframe): Water body geometries.
ppts (geodataframe): Pour points.
water_definition Label Definition
----------------------------- ---- ----------
None 0 No Waterbody Type value available.
Canal 1 An artificial watercourse serving as a navigable waterway or to
channel water.
Conduit 2 An artificial system, such as an Aqueduct, Penstock, Flume, or
Sluice, designed to carry water for purposes other than
drainage.
Ditch 3 Small, open manmade channel constructed through earth or
rock for the purpose of conveying water.
*Lake 4 An inland body of water of considerable area.
*Reservoir 5 A wholly or partially manmade feature for storing and/or
regulating and controlling water.
Watercourse 6 A channel on or below the earth's surface through which water
may flow.
Tidal River 7 A river in which flow and water surface elevation are affected by
the tides.
*Liquid Waste 8 Liquid waste from an industrial complex.
"""
lakes_df = lakes_df.to_crs(ppts.crs)
# reproject to projected CRS before calculating area
lakes_df['area'] = lakes_df.geometry.area
lakes_df['lake_id'] = lakes_df.index.values
# filter lakes smaller than 0.1 km^2
min_area = 100000
lakes_df = lakes_df[lakes_df['area'] > min_area]
lakes_df = lakes_df.dissolve().explode(index_parts=False).reset_index(drop=True)
lake_cols = lakes_df.columns
# filter out Point type geometries
lakes_df = lakes_df[~lakes_df.geometry.type.isin(['Point', 'LineString'])]
# find and fill holes in polygons
lakes_df.geometry = [Polygon(p.exterior) for p in lakes_df.geometry]
# find the set of lakes that contain confluence points
lakes_with_pts = gpd.sjoin(lakes_df, ppts, how='left', predicate='intersects')
# the rows with index_right == nan are lake polygons containing no points
lakes_with_pts = lakes_with_pts[~lakes_with_pts['index_right'].isna()]
lakes_with_pts = lakes_with_pts[[c for c in lakes_with_pts.columns if 'index_' not in c]]
# drop all duplicate indices
lakes_with_pts = lakes_with_pts[~lakes_with_pts.index.duplicated(keep='first')]
lakes_with_pts.area = lakes_with_pts.geometry.area
# use negative and positive buffers to remove small "appendages"
# that tend to add many superfluous inflow points
distance = 100 # metres
lakes_with_pts.geometry = lakes_with_pts.buffer(-distance).buffer(distance * 1.5).simplify(resolution/np.sqrt(2))
lakes_with_pts['geometry'] = lakes_with_pts.apply(lambda row: trim_appendages(row), axis=1)
return lakes_with_pts
def trim_appendages(row):
g = gpd.GeoDataFrame(geometry=[row['geometry']], crs='EPSG:3005')
geom = g.explode(index_parts=True)
geom['area'] = geom.geometry.area
if len(geom) > 1:
# return only the largest geometry by area
return geom.loc[geom['area'].idxmax(), 'geometry']
return row['geometry']
hydroLakes_fpath = '/home/danbot/Documents/code/23/bcub/input_data/BasinATLAS/HydroLAKES_polys_v10.gdb/HydroLAKES_polys_v10.gdb'
hydroLakes_clipped_fpath = os.path.join(base_dir, 'notebooks/data/geospatial_layers/HydroLAKES_clipped.gpkg')
lakes_df_fpath = os.path.join(base_dir, f'notebooks/data/geospatial_layers/{region}_lakes.geojson')
# the HydroLAKES CRS is EPSG:4326
lakes_crs = 4326
if not os.path.exists(hydroLakes_fpath):
err_msg = f'HydroLAKES file not found at {lakes_fpath}. Download from https://www.hydrosheds.org/products/hydrolakes. See README for details.'
raise Exception(err_msg)
# clip and reproject the HydroLAKES layer
if not os.path.exists(lakes_df_fpath):
print(' Creating region water bodies layer.')
t1 = time.time()
# import the NHN water body features
bbox_geom = tuple(region_polygon.to_crs(lakes_crs).bounds.values[0])
lake_features_box = gpd.read_file(hydroLakes_clipped_fpath,
bbox=bbox_geom)
# clip features to the region polygon
region_polygon = region_polygon.to_crs(lake_features_box.crs)
lake_features = gpd.clip(lake_features_box, region_polygon, keep_geom_type=False)
t2 = time.time()
print(f' Lakes layer opened in {t2-t1:.0f}s')
print(f' Creating lakes geometry file for {region}')
lakes_df = filter_lakes(lake_features, ppt_gdf, abs(resolution[0]))
lakes_df = lakes_df[~lakes_df.geometry.is_empty]
lakes_df.to_file(lakes_df_fpath)
n_lakes = len(lakes_df)
print(f' File saved. There are {n_lakes} water body objects in {region}.')
else:
lakes_df = gpd.read_file(lakes_df_fpath)
Warning
Below we apply some subjective criteria to improve the performance of the lake inflow point discovery:
Remove lakes smaller than 0.01 \(km^2\) to speed up the spatial join.
Only process lakes that contain confluence points in order to relocate points to river mouths.
Manipulate the lake polygons to smooth the edges – Where the stream raster disagrees with the NHN polygons it tends to generate spurious inflow points and this step is to mitigate the issue.
Require a minimum distance to existing confluence points (> 4 pixels).
lakes_df = lakes_df.to_crs(ppt_gdf.crs)
# reproject to projected CRS before calculating area
lakes_df['area'] = lakes_df.geometry.area
lakes_df['lake_id'] = lakes_df.index.values
# filter lakes smaller than 0.01 km^2
min_area = 10000
lakes_df = lakes_df[lakes_df['area'] > min_area]
Simplify lake geometries#
Misalignment of the derived stream network and the hydrographic information from the NHN produces spurious points when we try to find streams flowing into lakes. Simplifying (smoothing) the lake polygons trims long narrow segments classified as lake where feature alignment is most likely to occur.
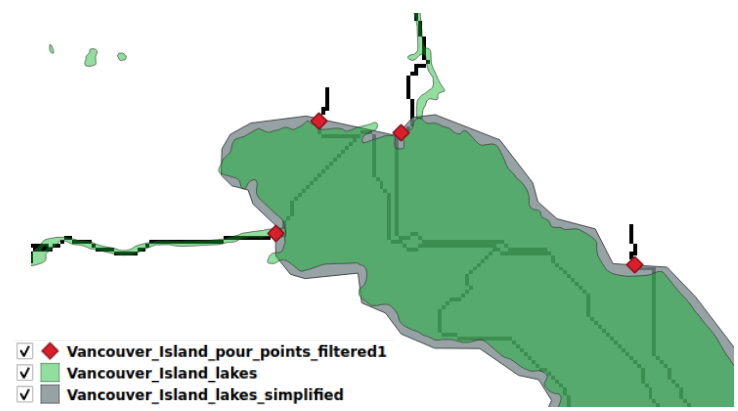
Fig. 8 A simplified polygon reduces the perimeter of the lake polygon in order to capture where stream lines cross the lake boundary.#
def trim_appendages(row):
g = gpd.GeoDataFrame(geometry=[row['geometry']], crs='EPSG:3005')
geom = g.copy().explode(index_parts=True)
geom['area'] = geom.geometry.area
if len(geom) > 1:
# return only the largest geometry by area
largest_geom = geom.loc[geom['area'].idxmax(), 'geometry']
return largest_geom
return row['geometry']
lake_ppts = ppt_gdf.clip(lakes_df)
filtered_ppts = ppt_gdf[~ppt_gdf['cell_idx'].isin(lake_ppts['cell_idx'])]
print(f' {len(filtered_ppts)}/{len(ppt_gdf)} confluence points are not in lakes ({len(ppt_gdf) - len(filtered_ppts)} points removed).')
20627/22556 confluence points are not in lakes (1929 points removed).
Find and add lake inflows#
We’ll only check lakes that have spurious confluences, the general idea is we shift the in-lake confluence to the inflow location. The method works best for large lake polygons and relatively smooth geometries where the stream network and NHN features align well, but it adds unnecessary points in other locations. A few examples of good and bad behaviour are shown below.
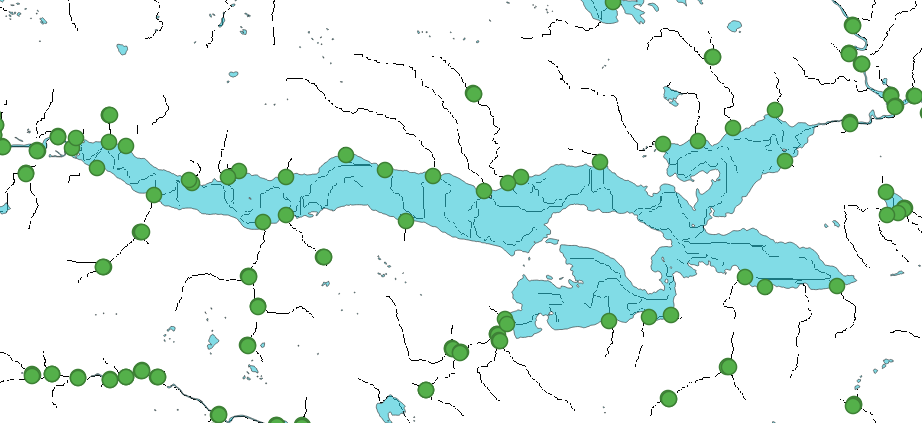
Fig. 9 Confluence points within lakes have been removed, while river mouths have been added.#
def find_link_ids(target):
x, y = target
stream_loc = stream.sel(x=x, y=y).squeeze()
link_id = stream_loc.item()
if ~np.isnan(link_id):
i, j = np.argwhere(stream.x.values == x)[0], np.argwhere(stream.y.values == y)[0]
return [i[0], j[0], Point(x, y), link_id]
else:
nbr = stream.rio.clip_box(x-resolution[0], y-resolution[0], x+resolution[0],y+resolution[0])
if np.isnan(nbr.data).all():
return None
raster_nonzero = nbr.where(nbr > 0, drop=True)
# Check surrounding cells for nonzero link_ids
xs, ys = raster_nonzero.x.values, raster_nonzero.y.values
for x1, y1 in zip(xs, ys):
link_id = nbr.sel(x=x1, y=y1, method='nearest', tolerance=resolution[0]).squeeze().item()
ix, jx = np.argwhere(stream.x.values == x1)[0], np.argwhere(stream.y.values == y1)[0]
# check if point is valid
if np.isnan(ix) | np.isnan(jx):
print(x, y, xs, ys, link_id)
print(ix, jx)
if ~np.isnan(link_id):
return [ix[0], jx[0], Point(x1, y1), link_id]
return None
def add_lake_inflows(lakes_df, ppts, stream, acc):
n = 0
tot_pts = 0
resolution = abs(stream.rio.resolution()[0])
crs = stream.rio.crs.to_epsg()
points_to_check = []
for _, row in lakes_df.iterrows():
n += 1
if n % 10 == 0:
print(f' Processing lake group {n}/{len(lakes_df)}.')
lake_geom = row['geometry']
# resample the shoreline vector to prevent missing confluence points
resampled_shoreline = redistribute_vertices(lake_geom.exterior, resolution).coords.xy
xs = resampled_shoreline[0].tolist()
ys = resampled_shoreline[1].tolist()
# find the closest cell to within 1 pixel diagonal of the lake polygon boundary
# this is the problem here.
# what's happening is for each interpolated point on the line,
# we look for the nearest pixel in the stream raster
# we should iterate through and find the nearest *stream pixel*
# and record it if
# i) it's not in a lake and
# ii) not on a stream link already recorded
px_pts = stream.sel(x=xs, y=ys, method='nearest', tolerance=resolution)
latlon = list(set(zip(px_pts.x.values, px_pts.y.values)))
latlon = [e for e in latlon if e is not None]
if len(latlon) == 0:
print('skip')
continue
# the line interpolation misses some cells,
# so check around each point for stream cells
# that aren't inside the lake polygon
pl = mp.Pool()
results = pl.map(find_link_ids, latlon)
results = [r for r in results if r is not None]
pl.close()
pts = pd.DataFrame(results, columns=['ix', 'jx', 'geometry', 'link_id'])
# drop duplicate link_ids
pts['CONF'] = True
pts = pts[~pts['link_id'].duplicated(keep='first')]
pts.dropna(subset='geometry', inplace=True)
points_to_check += [pts]
return points_to_check
Search along the boundary for lake-river confluences#
This step takes 18 minutes to process on a six core intel i7-8850H @2.6 GHz.
points_to_check = add_lake_inflows(lakes_df, filtered_ppts, stream, acc)
print(f' {len(points_to_check)} points identified as potential lake inflows')
Processing lake group 10/159.
Processing lake group 20/159.
Processing lake group 30/159.
Processing lake group 40/159.
Processing lake group 50/159.
Processing lake group 60/159.
Processing lake group 70/159.
Processing lake group 80/159.
Processing lake group 90/159.
Processing lake group 100/159.
Processing lake group 110/159.
Processing lake group 120/159.
Processing lake group 130/159.
Processing lake group 140/159.
Processing lake group 150/159.
159 points identified as potential lake inflows
Check that found points are not too close to an existing point#
def check_point_spacing(all_pts_df, ppts, ppt_gdf):
n = 0
all_pts = []
acc_vals = []
for i, row in all_pts_df.iterrows():
n += 1
pt = row['geometry']
if n % 250 == 0:
print(f'{n}/{len(ppts)} points checked.')
# index_right is the lake id the point is contained in
# don't let adjacent points both be pour points
# but avoid measuring distance to points within lakes
nearest_neighbour = ppts.distance(row['geometry']).min()
# check the point is not within some distance (in m) of an existing point
# 250m is roughly 10 pixels
min_spacing = 250
# check the point is not within some distance (in m) of an existing point
if nearest_neighbour > min_spacing:
all_pts.append(i)
x, y = pt.x, pt.y
acc_val = acc.sel(x=x, y=y, method='nearest').item()
acc_vals.append(acc_val)
all_points = all_points_df.iloc[all_pts].copy()
all_points['acc'] = acc_vals
return all_points
pts_crs = 3005
all_points_df = gpd.GeoDataFrame(pd.concat(points_to_check, axis=0), crs=f'EPSG:{pts_crs}')
all_points_df.reset_index(inplace=True, drop=True)
new_pts = check_point_spacing(all_points_df, filtered_ppts, ppt_gdf)
output_ppts = gpd.GeoDataFrame(pd.concat([filtered_ppts, new_pts], axis=0), crs=f'EPSG:{stream.rio.crs.to_epsg()}')
n_pts0, n_pts1, n_final = len(ppt_gdf), len(filtered_ppts), len(output_ppts)
print(f' {n_pts0-n_pts1} points eliminated (fall within lakes)')
print(f' {len(new_pts)} points added for lake inflows.')
print(f' {n_final} points after filter and merge. ({n_pts0-n_final} difference)')
output_ppts['region_code'] = region
# drop unnecessary labels
output_ppts.drop(labels=['cell_idx', 'link_id', 'OUTLET', 'CONF'], axis=1, inplace=True)
1929 points eliminated (fall within lakes)
134 points added for lake inflows.
20761 points after filter and merge. (1795 difference)
Format the river mouth points into a geodataframe and append it to the filtered set.
Save the output
# new_pts = gpd.GeoDataFrame(geometry=all_pts_filtered, crs=f'EPSG:{stream_crs}')
# pour_points = gpd.GeoDataFrame(pd.concat([filtered_ppts, new_pts], axis=0), crs=f'EPSG:{stream_crs}')
output_ppts.to_file(os.path.join(base_dir, f'notebooks/data/pour_points/{region}_pour_points_filtered.geojson'))